
Server-Side Tracking
Share
A website is a collection of publicly accessible web pages with related content, sharing a common domain. It is made up of codes, in most cases, usually a combination of HTML, CSS and JavaScript. A tracking script is normally added on the web pages' codes. When the website is loaded, the tracking script gets executed. Web visitors then trigger different events defined in the tracking script as they interact with the website, consequently providing behavioural data.
The goal is to track every activity happening on the website. The data collected here forms the basis of Digital Marketing. Data-driven business decisions heavily rely on it. From this setup, new potential improvements such as the user experience can be clearly defined.
While monitoring the website performance or health when visitors are using it may not be an issue, many have raised concerns, and rightfully so, regarding what exactly is being collected, and with whom is the data shared with. Basically, more transparency and accountability is being demanded.
The options of possible approaches to be adopted define what is considered as client-side/server-side tracking, first-party/third-party cookies. Other industry players have simply decided to shut everything tracking out, and so far they are making big wins. This is a serious challenge especially for the advertising sector.
The different aspects of web tracking will be looked at, delved deeper into, including implementation and challenges, then the summary to conclude on this urgent topic of today.
Highlight
The goal is to track every activity happening on the website. The data collected here forms the basis of Digital Marketing.
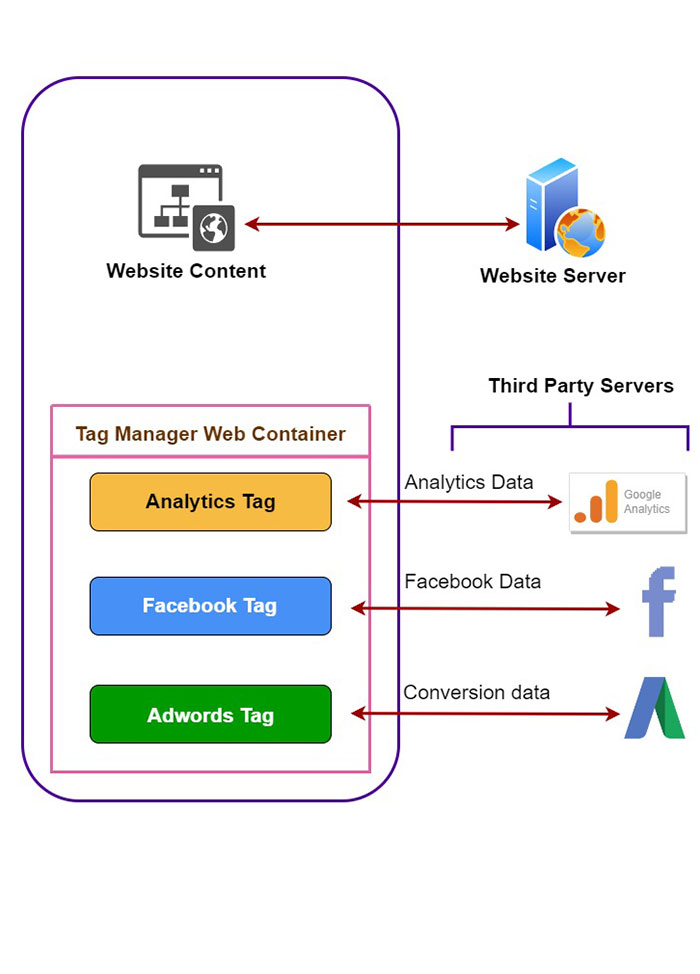
What is Server-side Tracking?
To properly understand server-side tracking, it is important to first talk about what it's not, the client-side tracking. This has been the most common approach where third party analytics tools have their JavaScript tracking codes on the web pages to directly collect tracking data, once executed in the user browsers. They also create third party cookies.
The data collected on your website can then be viewed in the different 3rd party analytics platforms. Several issues arise here. They include you not having full knowledge of the amount/severity of the data collected, how far the user data is shared without your consent, and these tracking scripts increasing the loading time, slowing down your website.
With the current digital world being highly conscious of data privacy, the risks presented by the client-side tracking cannot be wished away.
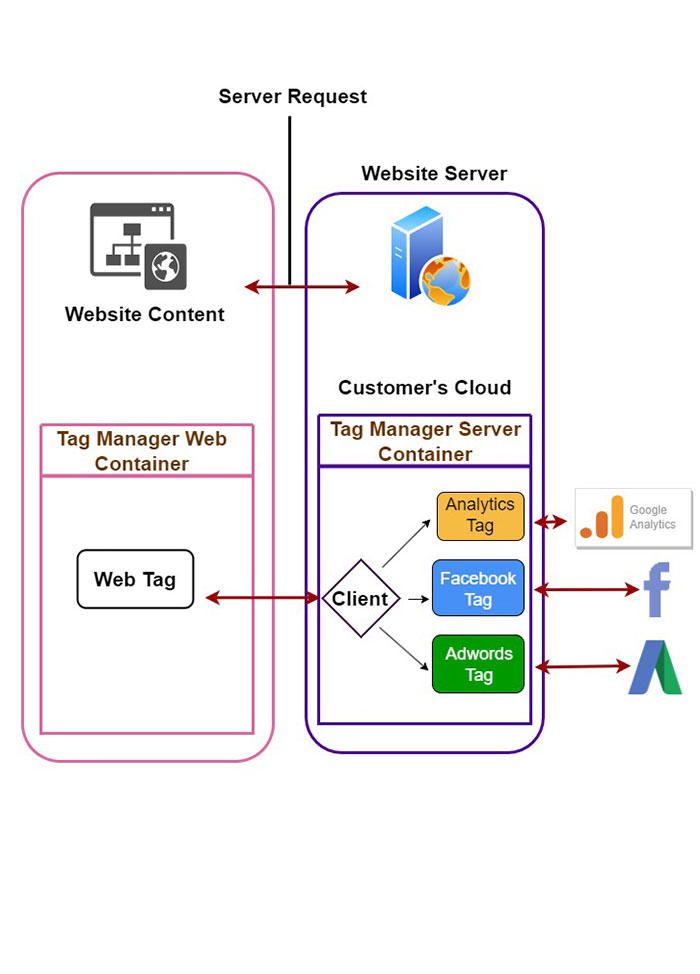
From a marketing perspective, the data gathered through these 3rd party analytics/cookies is necessary to make important business decisions especially in advertising. With the growing trend of adopting Adblockers,complete blocking of 3rd party cookies by many browsers including the largest in the market, Chrome, and Safari's Intelligent Tracking Prevention (ITP), marketers are missing a large chunk of tracking data.
It is quite evident a balance has to be reached, which will comply with the privacy laws such as GDPR and CCPA, but at the same time provide marketers with the necessary data.
Server-side tracking is a concept which simply consolidates all tracking data from your website to a singular server, your server. Once all the data is in your server, you have the monopoly to decide with whom to share what data, and easily adapt to any new regulatory changes.
This eliminates the risk fronted by 3rd party analytics tools. It also ensures that an organisation is future-proof when it comes to data privacy, considering that even first-party cookies on the client side are also being blocked by some browsers.
““By contrast, a server container doesn't run in the user's browser or on their phone. Instead, it runs on a server that you control. The server runs in your own Google Cloud Platform project - or in a different environment of your choosing - and only you have access to the data in the server until you choose to send it elsewhere.” — From Google Developers page on Server-side tagging
Importance of Server-side Tracking
Guaranteeing the security of users' data is of optimum goal for any website owner today. Server-side tracking helps to bypass adblockers as well as the ITP, with some level of success. This is a continuous process because everyday the ITP keeps getting more stringent.
An organization will also be in compliance with most regulations which require having full control of the data along with the knowledge of the data sharing. Marketers within the organization will also get more complete and accurate raw data.
Implementation
To implement server-side tracking, a custom subdomain is required with the same domain hierarchy as the main website. If a domain is track.com, the subdomain can be sstm.track.com. This way, the requests will be considered in the context of first-party, avoiding getting blocked.
To send requests to the server environment, a HTTP API endpoint is needed. Google Tag Manager (GTM) has a server container to meet this exact purpose. The server container is able to parse incoming HTTP requests into unified event formats. GTM is one of the several tag management tools available. As for the choice of server environment, this will depend on what an organization is already using, or what can be considered the easiest to implement. Options include the Google Cloud Platform, Amazon Web Services, Microsoft Azure or self-hosted environment.
The HTTP requests from a website need to be directed to the server environment using the HTTP API endpoint. This is the main idea from a technical perspective of what server-side tracking is all about, as shown in Figure 2.
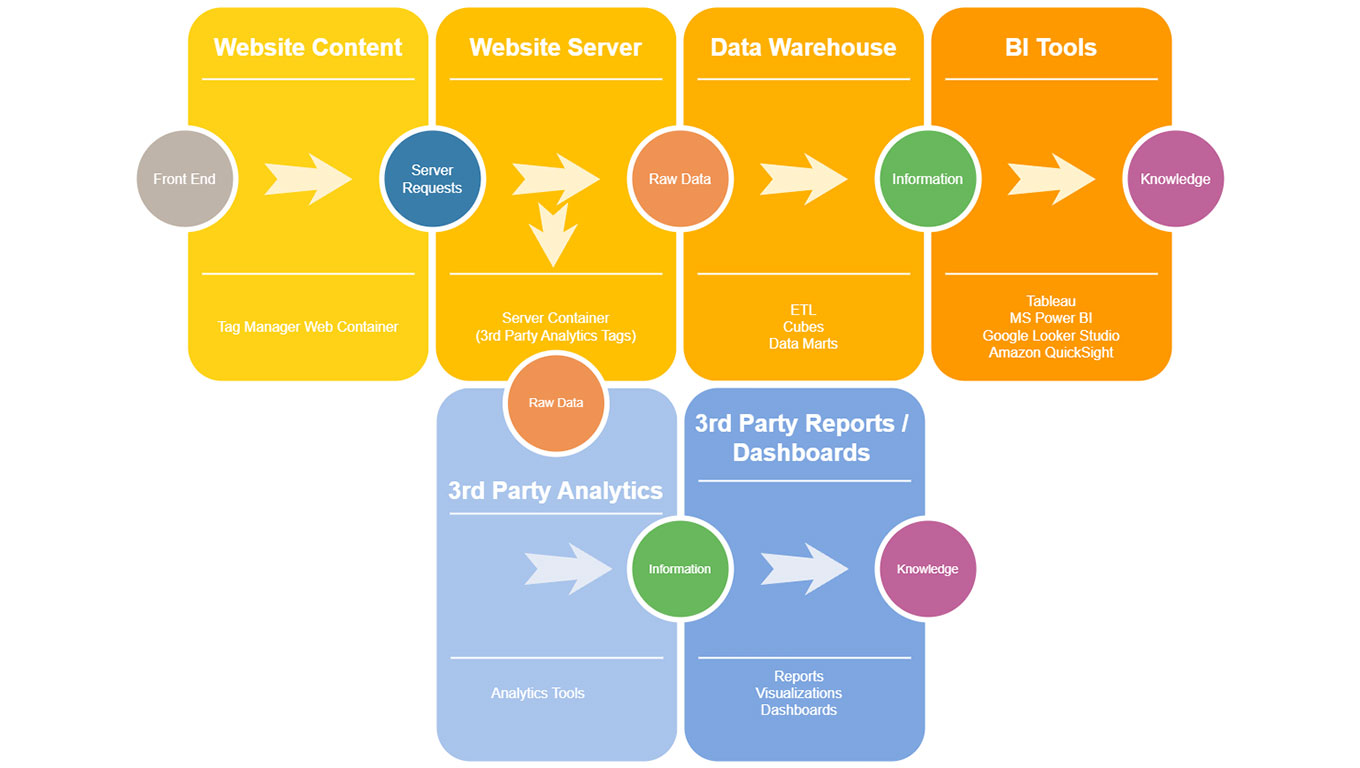
It is also possible for an organization to set up a two-way data pipeline for the web data in server-side tracking. From the illustration below, a complete Business Intelligence architecture can be done internally within the same cloud service, since most of them today offer the whole range of tools needed for data warehousing and BI analytics.
On the other hand, in comformity with the ideal server-side structure, the server can also share some raw data with third party analytics platforms. Since these platforms are highly optimized to analyse the raw data, in most cases they simplify the data analysis and answer the business needs. However, any limitations presented in terms of customizing the analysis can be overcome through the first setup. Should there be any doubt if data from one channel is wrong, then it will be possible to verify with the other route.
Challenges
While the advantages of server-side tracking are enviously glorious compared to client-side, the challenges of implementing it take away some joy. For starters, it requires high technical knowledge of how to set up everything.
Good knowledge of the server environment being used, the tag manager of choice, web development understanding, as well as JavaScript programming for some custom scripts. Its troubleshooting process isn't the smoothest to say the least. The added cost of server storage can also be a hindrance.
Summary
Server-side tracking addresses many important concerns related to data privacy, which has made it more relevant today, than it ever was. The gains to be made are huge, and are much welcomed by most industry players. It is possible for an organization to have its web data pipeline on its server, and only giving to the necessary recipients. This means that a separate internal business intelligence system can be set up with more information that will not be shared.
Since third party cookies are getting phased out completely, the next target at the moment is first party cookies on the client side. With server-side tracking, the risk and dependence poised by third-party cookies on the data it collects will be eliminated. An organization will also be a step ahead of the many tracking prevention tools because of the many advantages added such as increasing the cookie lifespan.
The availability of raw data in the server means that data scientists can deploy different models specific to an organisation, ranging from Anomaly Detection, Customer Churn Prediction, to even Recommendation Systems. All these can be done while adhering to the necessary rules and regulations.
However, the technical expertise and nitty-gritty required present some challenges to the whole process. With full understanding of what server-side tracking does, these challenges can be overcome.